常见问题
ArrayList 和 LinkedList 的区别
是否保证线程安全:二者都是不同步的,都不保证线程安全
底层数据结构:ArrayList 底层是 Object[]数组;LinkedList 底层用的是双向链表
插入和删除是否受元素位置的影响:
- ArrayList 采用数组存储,所以插入和删除元素受元素位置的影响
比如:执行 add(E e)方法时,会默认将指定的元素追加到此列表的末尾,这种时间复杂度就是 O(1),但是如果要在指定位置增加元素的话,时间复杂度就是 O(n-i),因为其余位置的元素都需要向后移动一位
- LinkedList 采用链表存储,所以对于 add(E e)方法来说,复杂度也近似 O(1),如果是要在指定位置插入元素的话,时间复杂度就近似 O(n),因为需要先移动到指定位置
是否支持快速随机访问:ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素
内存空间占用:ArrayList 的空间浪费主要体现在 list 的结尾会预留一定的容量空间,而 LinkedList 的空间话费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继、直接前驱以及数据)
RandomAccess接口
ArrayList 实现了此接口,RandomAccess 接口只是一个标识,标识这个类具有随机访问的功能
在 binarySearch() 方法中,他会判断传入的 list 是否实现 RandomAccess,如果是则调用 indexedBinarySearch() 方法,否则调用 iteratorBinarySearch()
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}ArrayList的扩容机制
ArrayList的构造函数
默认无参构造函数实际上初始化了一个空数组,当真正对数组进行添加元素操作时,才真正分配容量
即向数组中添加第一个元素时,数组扩容为 10
代码解析(Java8)
// 添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 获取最小扩容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 核心扩容方法
private void grow(int minCapacity) {
// 记录旧容量
int oldCapacity = elementData.length;
// 计算新容量,结果等于旧容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}System.arraycpoy()和 Arrays.copyOf()方法
- Arrays.copyOf:主要用于给原数组扩容,内部会新建一个数组,并返回该数组
- System.arraycopy:将原数组拷贝到你自己定义的数组里或原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置
/**
- 复制数组
- @param src 源数组
- @param srcPos 源数组中的起始位置
- @param dest 目标数组
- @param destPos 目标数组中的起始位置
- @param length 要复制的数组元素的数量
*/
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);ensureCapacity 和 ensureCapacityInternal
顾名思义,ensureCapacityInternal 是用户 ArrayList 内部调用的,ensureCapacity 是给外部调用的。当我们需要大量插入元素时,可以先调用 ensureCapacity 方法扩容,这样可以减少在增加元素过程中重新分配的次数
HashMap 与 HashTable 的区别
线程是否安全:HashMap 是非线程安全的,HashTable 是线程安全的,因为 HashTable 内部的方法基本都经过 synchronized 修饰
效率:因为线程安全的问题,HashMap 要比 HashTable 效率高一点
对 Null Key 和 Null Value 的支持:HashMap 支持,HashTable 不允许 Null,否则会抛出 NullPointException
初始容量大小和每次扩容大小的不同:
如果不指定初始值
Hashtable 的默认大小为11,之后每次扩容为原来的2n+1
HashMap 的默认大小为16,之后每次扩容为原来的2倍
如果给定了初始值
HashTable 会直接使用给定的初始值
HashMap 会将其扩充为2的幂次方
底层数据结构:jdk1.8之后的 HashMap,当链表长度大于阈值(默认为8)时(将链表转换成红黑树之前会判断当前数组的长度,如果小于64,那么会选择数组扩容,而不是转换成红黑树),将链表转化成红黑树,以减少搜索时间
tableSizeFor 保证 HashMap 的大小总为 2 的幂次方
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}这个方法的作用就是将当前数字 -1 后的结果 n 最高位后面的位都填充 1,得到的最后结果 +1 就会将最高位又进 1
举个例子
Cap = 5
N = 4,也既是 00000100
它的最后结果就是 00000111,也就是 7
最后 +1 进位,返回最终结果 8
HashMap和HashSet的区别
| 类型 | 存储内容 | 存放方式 | hashCode 计算方式 |
|---|---|---|---|
| HashMap | 存储键值对 | 调用 put 添加元素 | 使用键来计算 hashCode |
| HashSet | 仅存储对象 | 调用 add 增加元素 | 使用成员对象来计算 hashCode |
HashMap的底层实现
- Java8 之前
底层是数组和链表结合在一起使用的链表散列
HashMap 通过 key 的 hashCode 经过扰动函数处理后得到 hash 值,然后通过 (n-1)&hash 计算当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同的话就通过拉链法解决
扰动函数: 其实就是 HashMap 的 hash 方法,使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode 方法,换句话说,使用扰动函数之后可以减少碰撞
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}拉链法: 就是创建一个链表数组,数组中每一格就是一个链表,若遇到 hash 冲突,则将冲突的值加到链表中即可
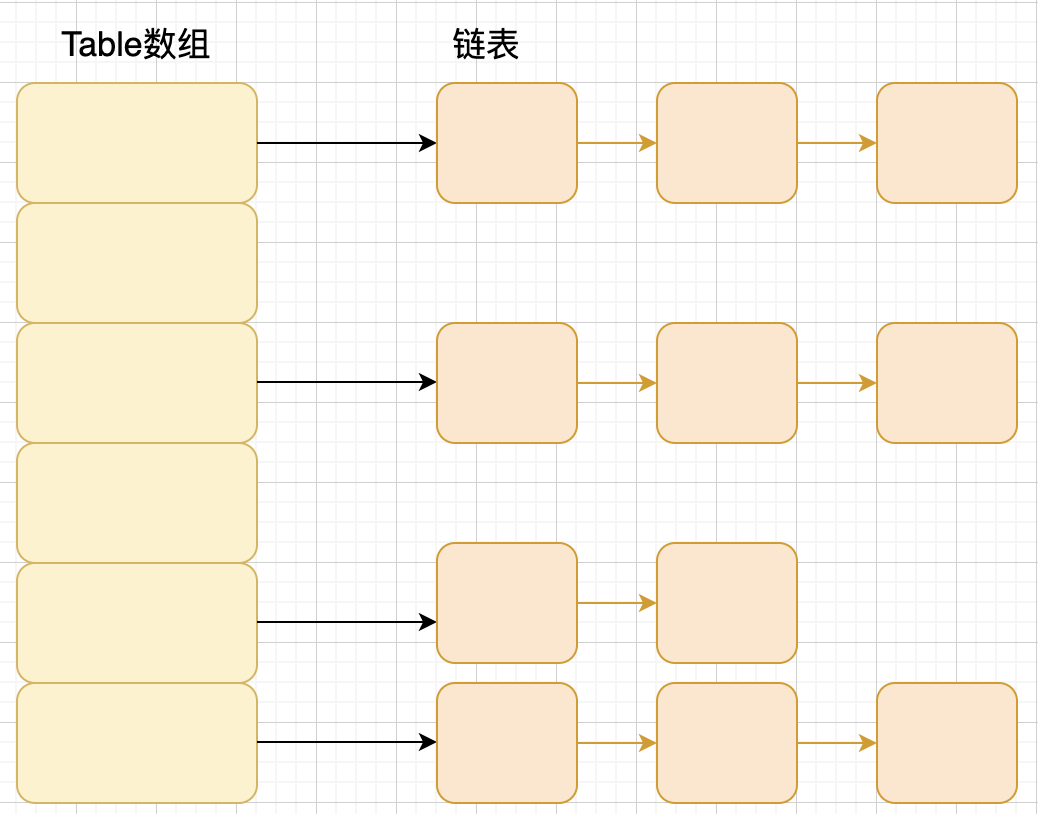
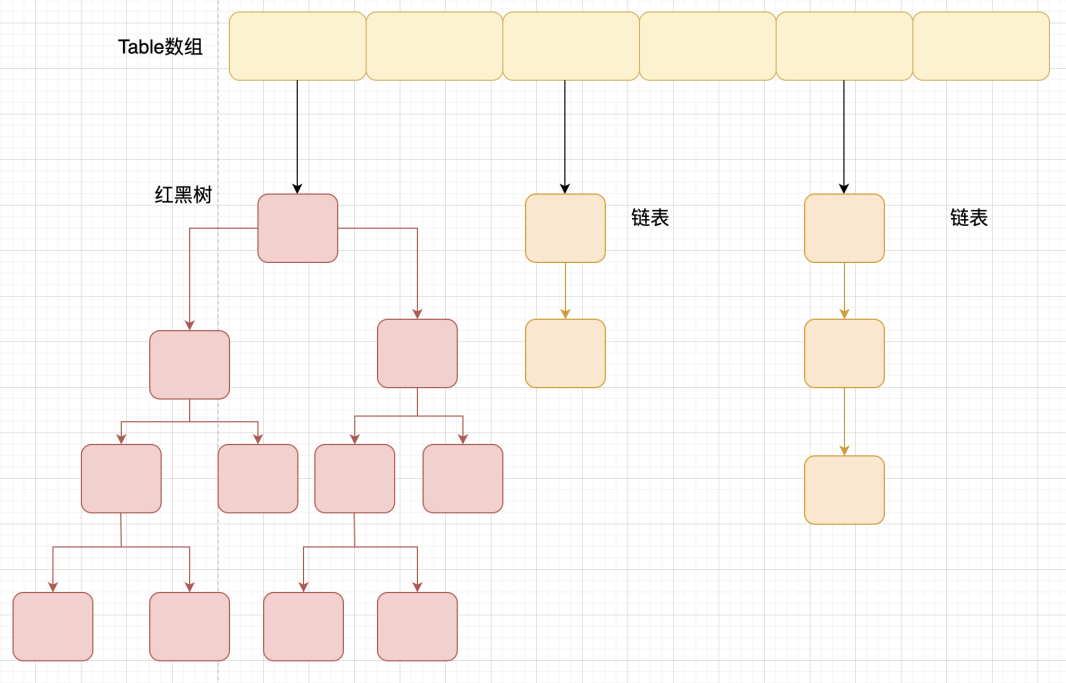
- Java8之后
当链表长度大于阈值时(默认为8),将链表转换为红黑树,以减少搜索时间(转换前会判断当前数组的长度,如果小于64,那么会选择先将数组扩容)
HashMap的长度为什么是2的幂次方
Hash 值的范围在-231~231-1之间,前后加起来大概40亿的映射空间,这样的数组内存是放不下的,所以我们还需要对数组长度取模运算,得到的余数就是要存放的位置,也就是数组下标
计算方式就是 hash%n,但是如果除数是2的幂次方的话,那么 hash%n 就等价于 (n-1)&hash
采用与操作相对于%操作来说会提高运算效率,这就解释了为什么 HashMap 的长度为什么是 2的幂次方
HashMap 多线程操作导致死循环(Java8之前)
ConcurrentHashMap 线程安全的具体实现方式
- JDK1.7

首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问
ConcurrentHashMap 是由 Segment 和 HashEntry 组成
Segment 实现了 ReentrantLock,所以 Segment 时一种可重入锁
一个 ConcurrentHashMap 包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 的元素,当对 HashEntry 修改时,必须获得对应的 Segment 锁
- JDK1.8
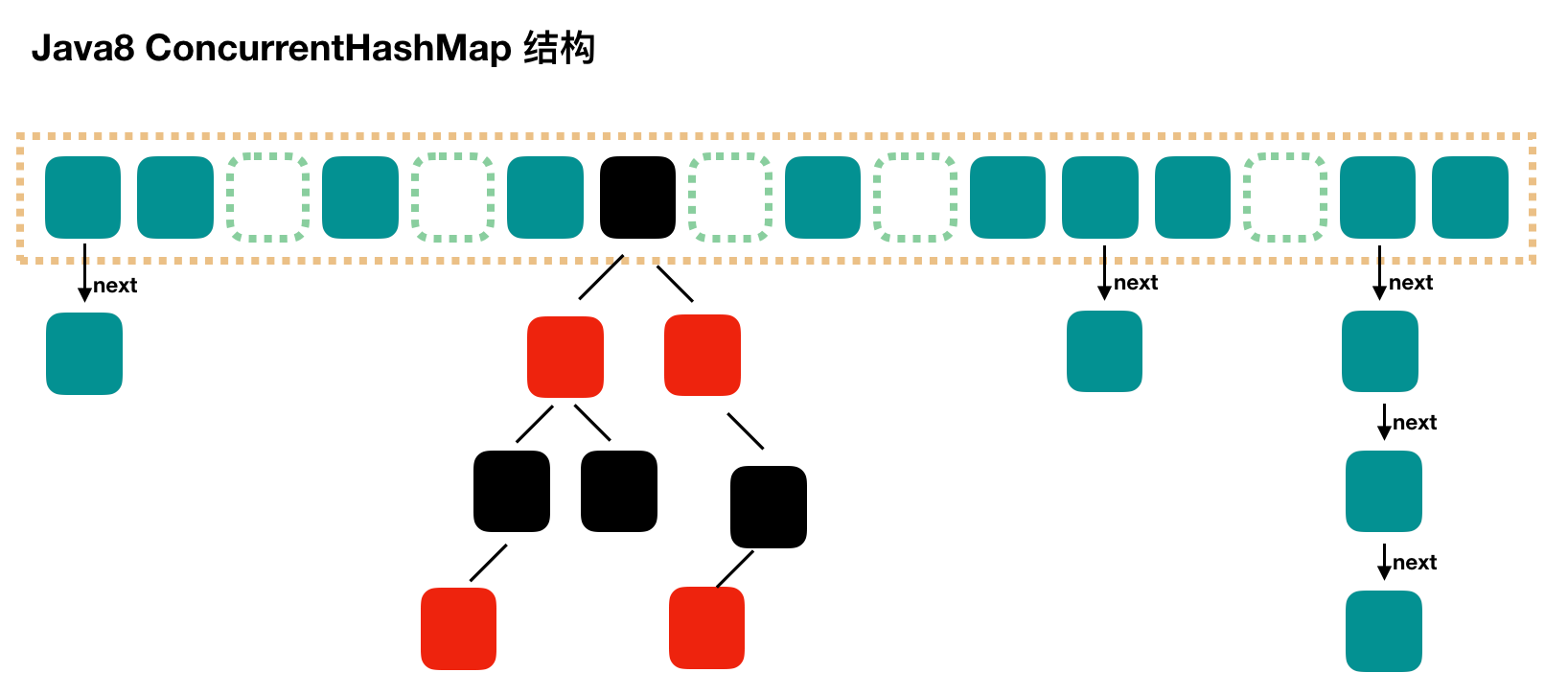
ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构也是数组+链表/红黑树的形式,Java8在链表长度超过一定阈值时将链表(O(N))转换成红黑树(O (logN))
synchronized 只锁定当前链表或者红黑树的首节点,所以只要 hash 不冲突,就不会产生并发