Kafka 为什么这么快?RocketMQ 哪里不如 Kafka?
Kafka 为什么这么快?RocketMQ 哪里不如 Kafka?
RocketMQ 在设计上参考了 Kafka,架构上更简单,功能更加丰富
看起来似乎是 RocketMQ 更加能打
但是 Kafka 一直没有被淘汰,说明 RocketMQ 必然有着不如 Kafka 的地方
是什么呢?
性能!严格来说是吞吐量
数据显示,RocketMQ 每秒能处理 10W 量级的数据,而 Kafka 则是 17W
快则快矣,但其实也并没有拉开量级的性能差距
消息从消息队列的磁盘发送到消费者,过程是怎么样的?
消息队列的进程为了防止进程崩溃后丢失消息,一般不会放在内存里,而是放在磁盘上
操作系统分为用户空间和内核空间
程序处于用户空间,硬盘则属于硬件
操作系统本质上就是程序和硬件之间的中间层,程序需要通过操作系统去调用硬件能力
如果用户想要将数据从磁盘(消息实际存储的地方)发送到网络(消费者),一般来说会经过这么几个步骤
- 程序发起 read () 请求,消息从磁盘拷贝到内核空间中的内核缓冲区
- 消息从内核缓冲区拷贝到用户空间的用户缓冲区
- 程序发起系统调用 write () 请求,消息从用户缓冲区拷贝到内核空间的 socket 缓冲区
- 最后,消息从 socket 缓冲区拷贝到网卡上,发送到网络中,最终到达消费者
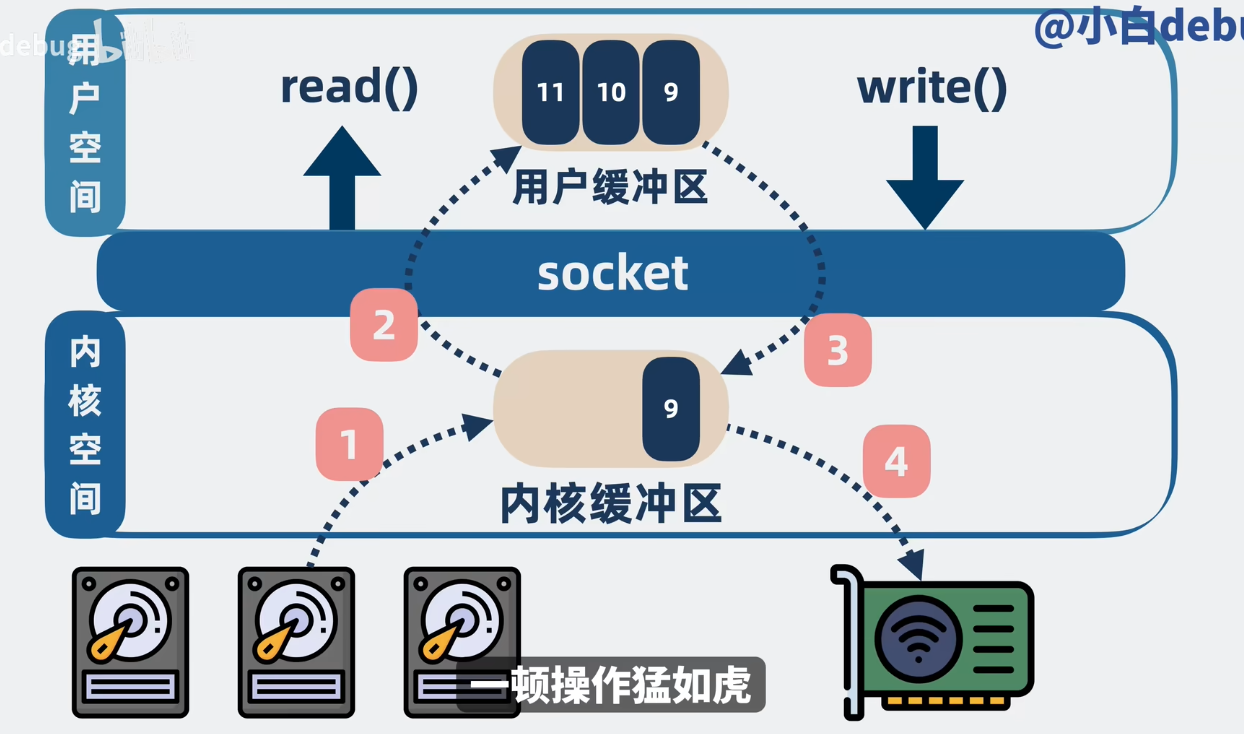
整个过程总共有 2 次系统调用、4 次用户空间和内核空间的切换、4 次数据拷贝
同样一份数据来回拷贝,效率低下
零拷贝技术
常见的方案有两种,分别是 mmap 和 sendfile
mmap
mmap 是操作系统提供的一个方法,可以将内核空间的缓冲区映射到用户空间
使用它后,上文提到的发送流程就会产生变化
- 程序发起 mmap () 请求,消息从磁盘拷贝到内核空间中的内核缓冲区
- 消息从内核缓冲区映射到用户空间的用户缓冲区(这里不需要拷贝)
- 程序发起系统调用 write () 请求,消息从内核缓冲区拷贝到内核空间的 socket 缓冲区
- 最后,消息从 socket 缓冲区拷贝到网卡上,发送到网络中,最终到达消费者
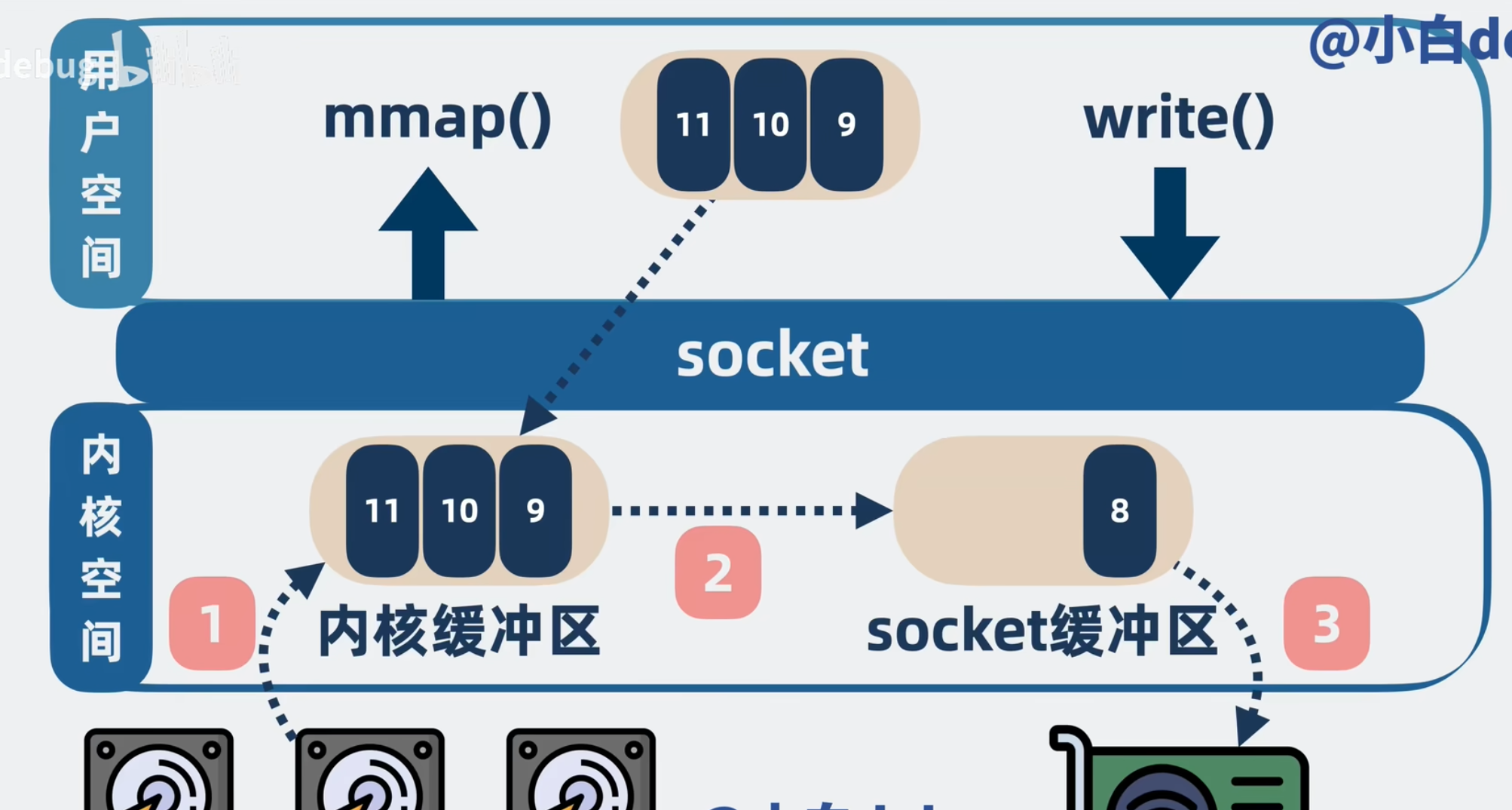
整个过程总共有 2 次系统调用、4 次用户空间和内核空间的切换、3 次数据拷贝
省下了 1 次数据拷贝
相信大家也发现了,零拷贝技术并不意味着 1 次拷贝都没有,它只是说在用户空间到内核空间这个过程不需要拷贝
sendfile
顾名思义,sendfile 就是用来发送文件数据的
- 程序发起 sendfile () 请求,消息从磁盘拷贝到内核空间中的内核缓冲区
- 消息从内核缓冲区通过 SG-DMA 直接拷贝到网卡
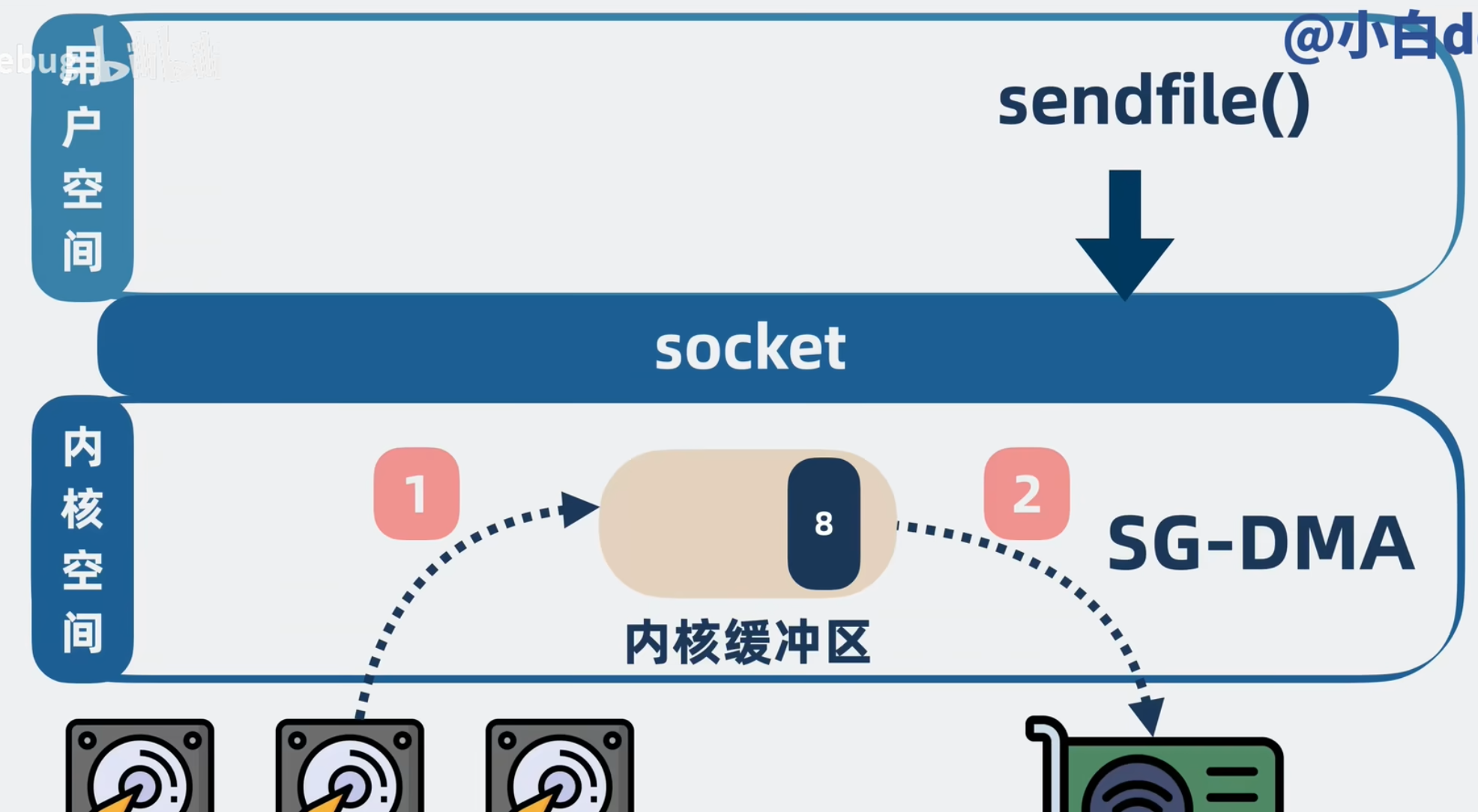
整个过程总共有 1 次系统调用、2 次用户空间和内核空间的切换、2 次数据拷贝
这里的零拷贝指的是 0 CPU 拷贝,sendfile 参与的场景下都不是 CPU 直接参与的拷贝,而是 DMA 控制器在干活,不耽误 CPU 跑程序
所以说,Kafka 的性能为什么比 RocketMQ 好?
这是因为 RocketMQ 使用的是 mmap 技术,而 Kafka 则选择了 sendfile
Kafka 以更少的拷贝次数以及系统内核切换次数获得了更好的性能
那么问题来了,RocketMQ 为什么不使用 sendfile 技术呢?
难道是阿里的程序员连抄作业都不会?
这里我们需要看一下这两个函数的具体用法
int sendfile(int out_fd, j _fd, off_t* offset, int count);
// num = sendfile(xxxx);
void *mmap(void *addr, int length, prot, flags, fd, off_t offset);
// buf = mmap(xxxx);仔细分析就能发现
mmap 返回的是数据的具体内容,应用层能获取到消息内容并进行逻辑处理
而 sendfile 则是成功发送了几个字节数,具体发送什么则是什么都不知道
RocketMQ 的某些功能特性,则需要获取到消息的具体内容,比如说将消费失败的消息重新投递到死信队列中
而 Kafka 为了极致的性能,则选择放弃了这些特性
没有一种架构是完美的,一种架构往往用于适配某些场景,很难做到既要又要
做架构,做到最后都是在做折中